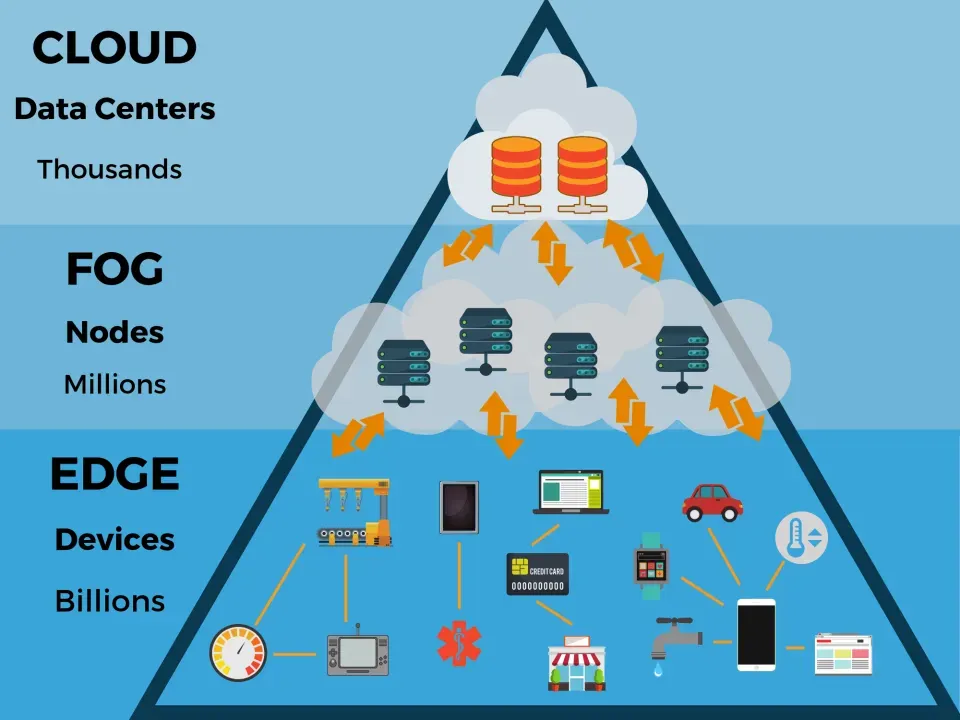
Edge computing proximity is reshaping how organizations process data by bringing computation closer to where it is generated, enabling faster decisions, lower latency, smarter operations, and more efficient use of distributed resources. This approach delivers edge latency reduction, accelerates IoT edge computing deployments, enables near-edge processing so sensor data can be analyzed locally before transmission, and supports offline operation when connectivity is intermittent. It also helps balance the roles of edge devices and gateways with more powerful, nearby compute nodes, reducing bandwidth consumption, improving data privacy, and enabling graceful degradation during partial outages. Most architectures follow a tiered model—sensors and tiny edge devices feed gateways or micro data centers, which perform local analytics and ML inference before selectively forwarding results to the cloud, a consideration of edge vs cloud computing tradeoffs. Across manufacturing, healthcare, and smart cities, adopting proximity at the edge can unlock faster insights, greater resilience, safer and compliant data governance, and new business models powered by localized intelligence.
Seen through a different lens, this idea is about localized computing at the network edge, where data is processed close to its source. In practice, practitioners describe an edge-centric, distributed infrastructure that emphasizes on-device processing, near-edge analytics, and gateway-backed micro data centers to minimize data movement and latency. The cloud remains a vital layer for long-term storage, centralized analytics, and governance, but tasks are staged across an edge-to-cloud continuum to optimize speed, privacy, and resilience.
Edge Computing Proximity: Accelerating Decisions at the Source
Edge computing proximity reshapes how data is processed by bringing computation closer to where it’s generated. By reducing the distance data must travel, organizations experience edge latency reduction that enables near real-time analytics and faster business outcomes. In environments with smart devices—manufacturing sensors, healthcare monitors, or city infrastructure—the ability to make immediate decisions without funneling every data point to a distant cloud is a practical necessity. This approach also helps optimize bandwidth usage and supports privacy-minded workflows by performing sensitive processing at or near the data source, often through edge devices and gateways that host lightweight analytics and local data filtering.
A practical, tiered architecture underpins proximity. Devices at the edge generate data, which is then processed at nearby gateways or micro data centers in a near-edge processing model. This tiered setup allows IoT edge computing to run real-time inference and local analytics, while the core cloud handles long-term storage and global model updates. The result is a balanced spectrum between edge vs cloud computing, where compute resources are allocated based on latency, privacy, and bandwidth needs, rather than a binary on/off choice.
IoT Edge Computing and Near-Edge Processing: From Devices to Gateways and Cloud
IoT edge computing situates intelligence where data originates, enabling edge devices and gateways to perform substantial processing close to sensors and cameras. Near-edge processing reduces data volume sent upstream, trims latency, and lowers cloud bandwidth costs, all while safeguarding privacy by keeping sensitive information local when possible. In practice, this translates to faster alerts, smarter local control loops, and more resilient operations in sectors like manufacturing, healthcare, and smart cities.
Implementing effectively means designing for a layered, interconnected ecosystem. Edge latency reduction is achieved by distributing workloads across device level processing, edge gateways, and micro data centers, with cloud resources reserved for training, orchestration, and archival analytics. By embracing data locality and governance—filtering and summarizing at the edge—you can maintain governance while still leveraging the cloud for scale. This approach aligns with a pragmatic edge vs cloud computing decision framework and supports ongoing evolution toward secure, interoperable edge platforms across industries.
Frequently Asked Questions
What is edge computing proximity, and how does it enable edge latency reduction in IoT edge computing deployments?
Edge computing proximity means placing compute resources close to data sources such as sensors and devices to shorten data travel and reduce latency. By using near-edge processing across edge devices and gateways in IoT edge computing deployments, you can achieve significant edge latency reduction, lower bandwidth use, and improved privacy, while still leveraging cloud services for longer-term analytics when appropriate. This multi-tier architecture—devices at the edge, gateways with local analytics, and central cloud—enables real-time decisions to happen locally with only meaningful results sent upstream.
How do you decide between edge vs cloud computing for proximity-sensitive workloads, and what role do edge devices and gateways play in near-edge processing?
When workloads are sensitive to latency, bandwidth, or privacy, edge devices and gateways enable near-edge processing and keep critical decisions close to data sources. This makes edge computing proximity ideal for fast responses while the cloud handles heavy analytics and model training when needed. A practical approach uses a tiered architecture: run time-critical, privacy-conscious tasks at the edge; perform bulk analytics in the cloud; and orchestrate between layers to balance proximity, data governance, and efficiency.
| Aspect | Key Points |
|---|---|
| Definition | Edge proximity means physical and network closeness between data sources (sensors/devices) and compute resources, reducing data travel time and enabling near real-time insights while reducing pressure on central data centers and core networks. |
| Core benefits |
|
| Architecture shapes |
|
| Proximity in practice scenarios |
|
| Decision framework |
|
| Implementation Best Practices |
|
| Future Trends |
|
Summary
Edge computing proximity is a foundational concept that explains why organizations bring compute closer to where data is generated. It highlights how reduced latency, bandwidth savings, privacy gains, resilience, and localized intelligence can transform operations across industries. By adopting a tiered architecture and practical best practices, organizations can optimize performance, governance, and security while enabling real-time insights at the edge.


